Dateirettung aus Fragmenten
Bekanntlich werden Dateien fast nie im Dateisystem ungeteilt und fortlaufend gespeichert, sondern in Fragmente gesplittet. Die Art und Weise, wie die Datei gesplittet und zusammengesetzt wird, hängt vom Betriebssystem ab. Im NTFS-System, beispielsweise, ist die MFT-Dateitabelle für eine korrekte Dateispeicherung und –lesen (evtl. Aufteilung in und Zusammensetzung der Fragmente) verantwortlich. Bei Fehlern, jedoch, können sich die Links von der MFT zu Dateifragmente verlieren, was zum Verlust der Datei seitens des Betriebssystems führt. In diesem Artikel wird es beschrieben, wie man eine zerrissene Datei zusammensetzen kann. |
 |
Wir führen hier ein leichtes Beispiel einer .bmp Datei auf. Die Fragmente dieser Datei werden wegen Beschädigung des MFT-Eintrags als eine Datei nicht mehr gelesen und werden durch Betriebssystem als zerstört erkannt. Hier versuchen wir die Teile manuell zusammenzukleben und damit die Datei wiederherzustellen. Zur Analyse und Editieren wird das Programm CI Hex Viewer benutzt. Im Laufe des Analyse- und Editieren-Prozesses geben wir Tipps zur Softwarenutzung.

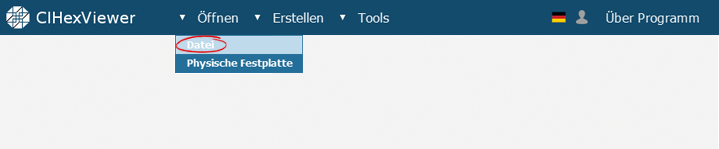
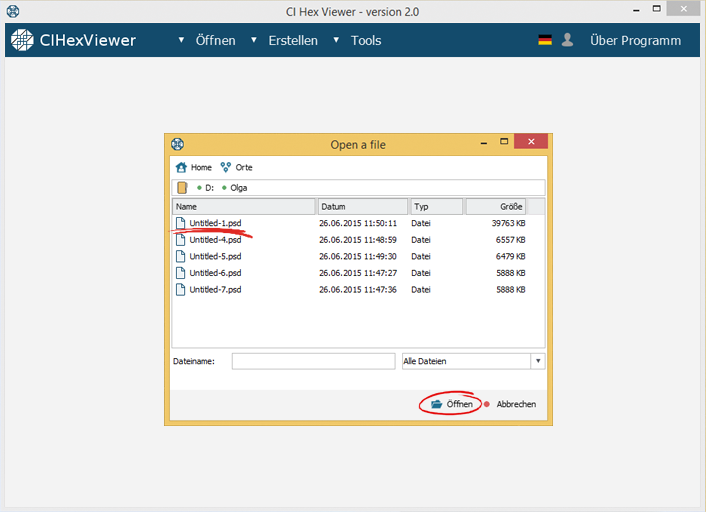
Zuerst öffnen wir das erste gefundene Fragment der Datei im Programm. Dazu drücken wir Öffnen, optieren Datei aus der Drop-Down-Liste und wählen die nötige Datei im Dialogfenster.

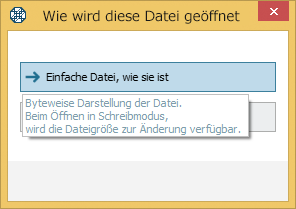
Abweichend von Speicherabbilddateien und Dateien virtueller Festplatten, werden reine Dateien als Einfache Datei, wie sie ist ins Programm geladen. Das lässt die Tools für Dateien bei der Arbeit im Editiermodus benutzen, einschließlich Tools für Änderung der Dateigröße.

Wir beginnen mit einer detaillierten Analyse des Dateiheaders. Analyse von Dateiheadern lässt die Datenintegrität überprüfen, sowie Ursachen zur Dateibeschädigung bestimmen.
Die Struktur des .bmp-Headers ist wie folgt:
Offset |
Feldlänge |
Feldname |
Feldwert (im aufgeführten Beispiel) |
0x0000 |
Word |
Dateikennung |
Immer 0x4D42; im Textbereich steht die Kennung „BM“ |
0x0002 |
DWord |
Dateigröße (Bytes) |
0x000E1036 (921654 Bytes) |
0x0006 |
Word |
Reserviert, immer Null |
0x0000 |
0x0008 |
Word |
Reserviert, immer Null |
0x0000 |
0x000A |
DWord |
Länge des Dateiheaders |
0x00000036 (54 Bytes) |
0x000E |
DWord |
Größe von |
0x00000028 (40 Bytes) |
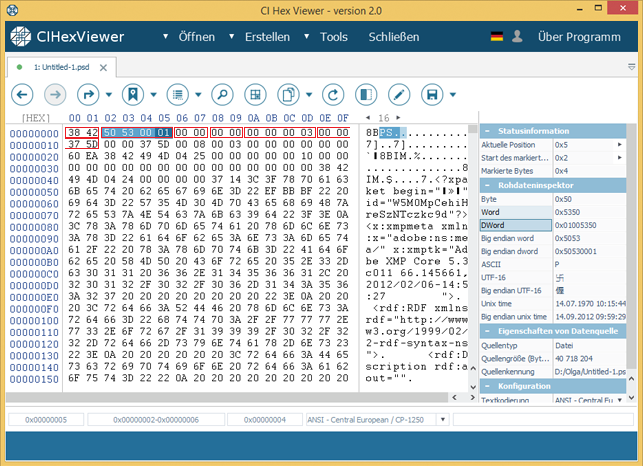
Die Werte hexadezimaler Datenfelder lassen sich leicht im Rohdateninspektor lesen. Zur Anzeige des Feldwertes im Rohdateninspektor den Cursor an den Feldanfang stellen und den entsprechenden Datentyp in der Inspektor-Tafel finden.
Der Wert des 4-Byte-Feldes ab Offset 0x02 in der Richtung Little-Endian ist, zum Beispiel, in der Zeile DWord des Inspektors zu finden.
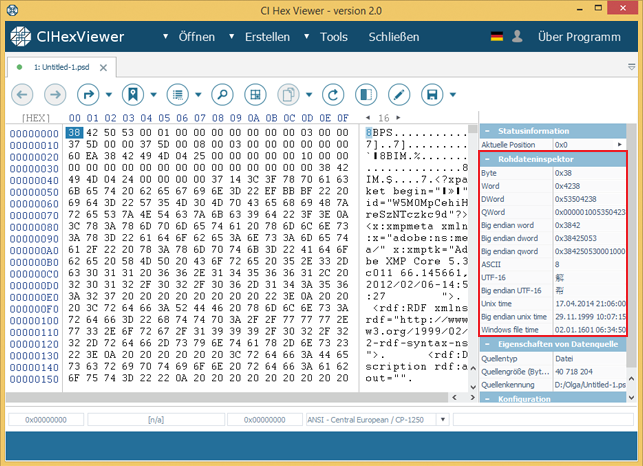
Zur Bequemlichkeit des Anschauens kann die Zeilenlänge nach Bedarf angepasst werden. Zur Ausdehnung bzw. zur Verkürzung der Zeile wird der entsprechende Pfeil in der rechten oberen Ecke gedrückt oder die nötige Zeilenlänge ins Drop-Down-Kästchen eingegeben.
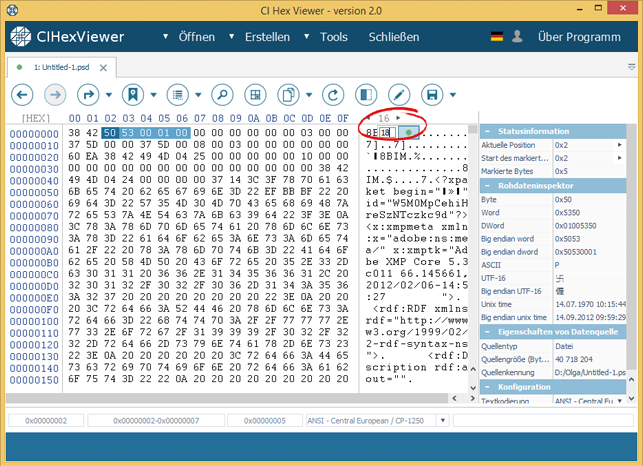
In unserem Fall, zum Beispiel, ist es unbequem das 4-Byte-Feld ab Position 0x0E anzuschauen, weil sich die ersten zwei Bytes in einer Zeile und die anderen Zwei in der nächsten Zeile befinden. Wir verlängerten die Reihe bis 18 Bytes pro hexadezimale Zeile.

Im Feld 0x0E-0x11 stehen 0x28 Bytes, was die Länge des .bmp-Infoheaders bezeichnet. Mit der letzten Position des Infoheaders endet sich der Header und die Daten der .bmp-Datei beginnen. Zum Überprüfen des Wertes übergehen wir zum Headerende. Dazu markieren wir 4 Bytes ab Position 0x11 in Richtung von Little-Endian-Link und aus der Drop-Down-Liste zum Positionswechsel wählen wir Link folgen. Der Wert des hexadezimalen Feldes wird durch Programm wie ein Wert der neuen Position gelesen. Wir geben die Einheit zum Ausrechnung neuer Position als Bytes und die Richtung zum Übergang als Vorwärts ab der aktuellen Position ein.
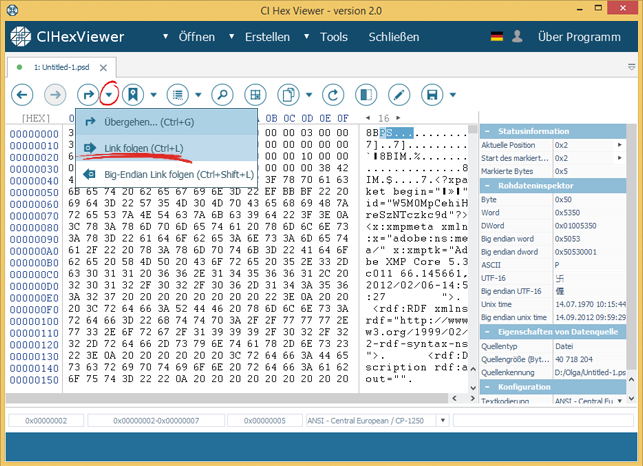
Mit der Position, auf die wir übergegangen sind, beginnen schon die Daten, was Ende des Headers bezeichnet.
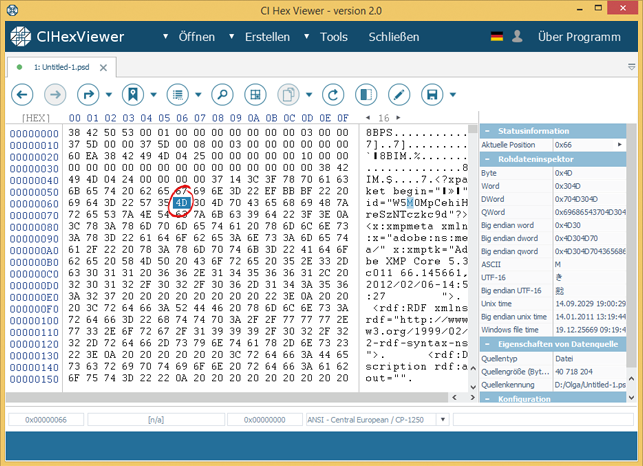
Infolge der Analyse wurde Dateiunvollständigkeit festgestellt. Die volle Dateigröße ist, nach dem Header, 921654 Bytes, und im Rohdateninspektor, sowie in Dateneigenschaften stehen nur 412 922 Bytes.
Das lässt uns vermuten, dass das zweite Fragment, die Fortsetzung des ersten Fragmentes ist.
Wir öffnen den Tab des zweiten Fragmentes und finden hier keinen Dateiheader. Die Dateigröße ist dabei (laut der Quelleneigenschaften) 508 731 Bytes, was mit 412 922 Bytes des ersten Fragmentes die ganze Größe der zerstörten Datei zusammenstellt.
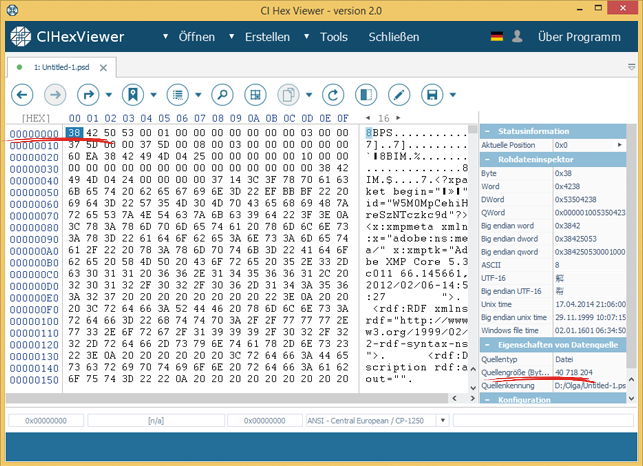

Mit diesen Ergebnissen versuchen wir die Dateifragmente zu kleben. Dazu schalten wir die Datei in den Editieren-Modus mit dem Knopf Daten ändern um.
 durch die im Editieren-Modus gemachten Datenänderungen werden Datenquellen modifiziert. Die Fehler beim Editieren können zu einem irreversiblen Datenverlust führen.
durch die im Editieren-Modus gemachten Datenänderungen werden Datenquellen modifiziert. Die Fehler beim Editieren können zu einem irreversiblen Datenverlust führen.
m Editiermodus stellen wir den Cursor ans Dateiende. Dazu drücken wir Übergehen und geben im Dialogfenster zum Positionswechsel die schon bekannte Dateigröße aus der Inspektor-Tafel als die Anzahl von Bytes.
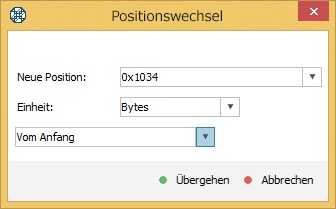
Mit dem Cursor am Dateiende fügen wir das zweite Fragment ans Erste an. Dazu drücken wir Datei anfügen aus der Toolbar für Dateneditieren.
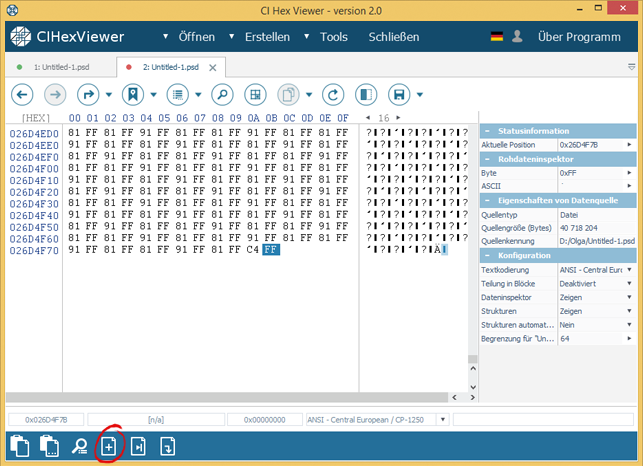
Mit dem Dialogfenster wählen wir die Datei des zweiten Fragmentes. Die Daten dieser Datei werden so wie sie sind zur Quellendatei hinzugefügt.
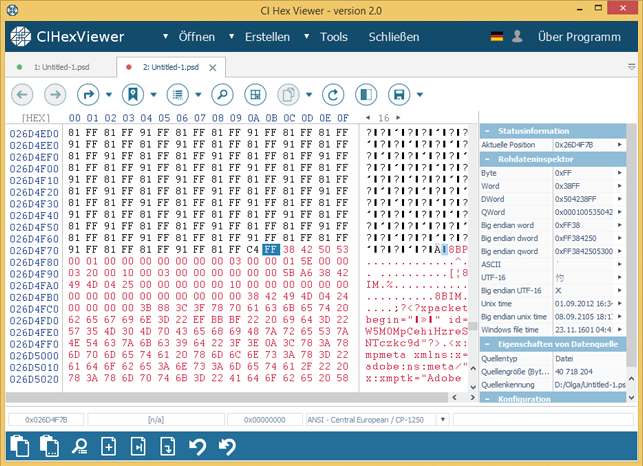
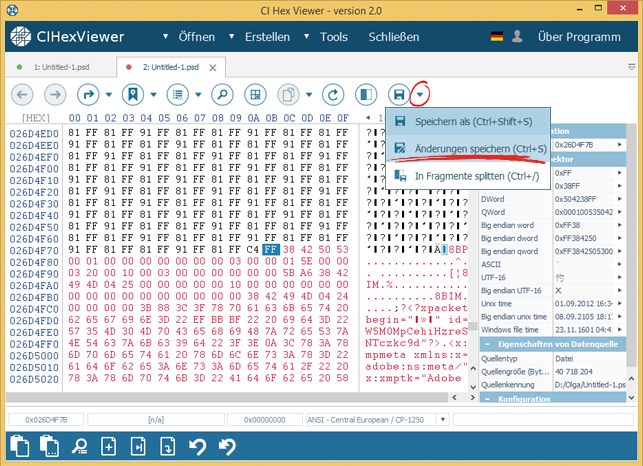
Wir speichern jetzt die Änderungen drückend auf den Knopf Änderungen speichern.
Dabei aktualisieren wir die Daten in der Quellendatei, drückend auf den Knopf Aktualisieren.
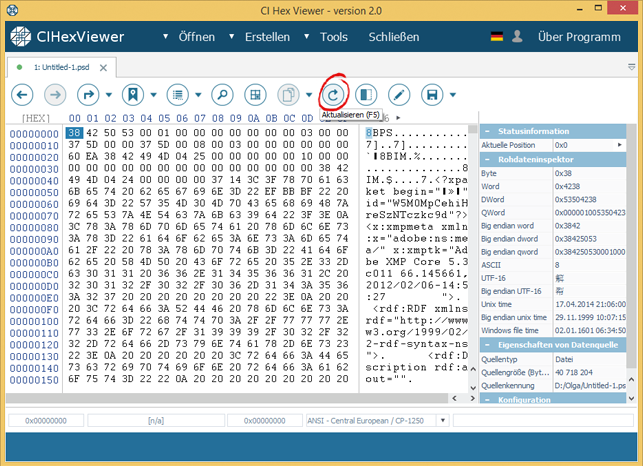
Als Ergebnis bekommen wir die komplette Datei.
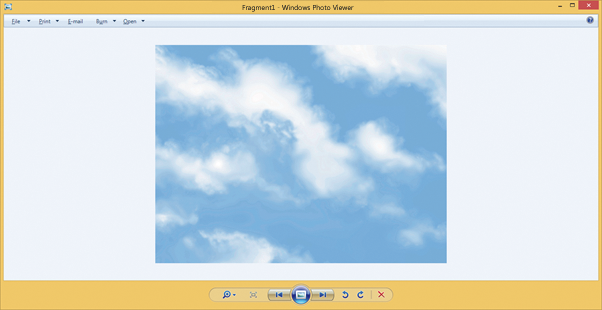
Fazit:
Wiederherstellung der zerstörten Datei wurde in mehreren Schritten durchgeführt. Zuerst wurde die Datei des ersten Fragmentes geöffnet und analysiert. Es wurde durch die Analyse roher Daten festgestellt, dass die zerstörte Datei unvollständig ist. In der zweiten Etappe wurde das fehlende Fragment an die Datei mit dem entsprechenden Editiertool angehängt. Die oben angeführten Maßnahmen lassen im Groß und Ganzen die in Fragmente gesplitteten Dateien zusammenzufügen.