File recovery from fragments
As known, the file system almost never stores a file as a whole and continuous file, and rather splits it into fragments. The way to store and gather the fragments depends much on the file system itself. For example, NTFS has the Master File Table (MFT) responsible for correct file storing and reading, and in particular, splitting and compiling of the fragments. In case of failures, however, references from the MFT to file fragments can be lost leading to loss of the file as a whole. In this article, you will find a guide how to recover a file split into fragments. |
 |
We give a simple example of a .bmp file here. Because of the MFT record damage, the system won’t read the file fragments as a whole file, and on the contrary identifies this file as corrupted. We are going to put together the file fragments manually and to recover the file in this way. We use CI Hex Viewer software for a preliminary data analysis and further file editing and give tips on software use in the process.

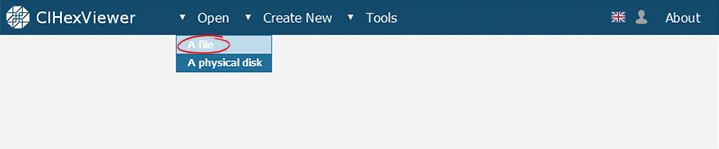
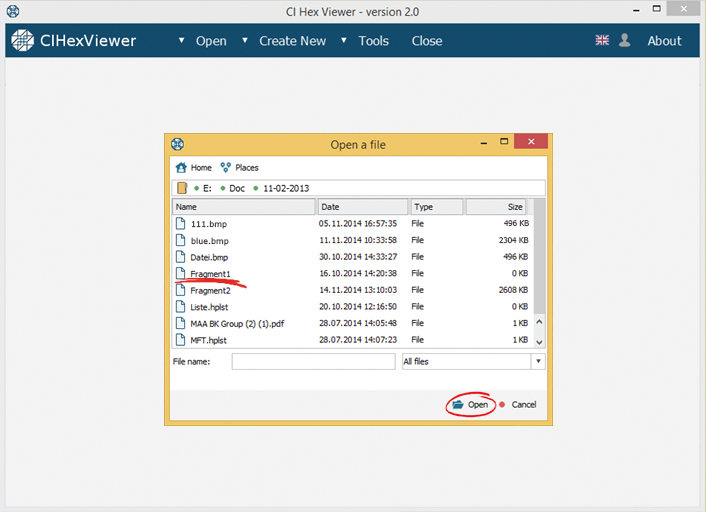
To start with, we open the first of the found file fragments in the program. To do this we press Open, select File from the drop-down list and choose the necessary one from the dialog window.

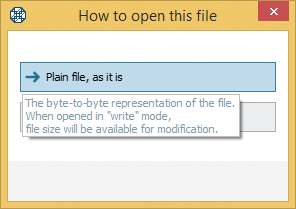
As compared to disk images and virtual disk files, simple files are opened into the program as Plain file as it is. This allows applying the tools for work with files in the editing mode of the program, including those for file size modifications.

We begin with a detailed preliminary analysis of the file header. File header analysis lets you examine data integrity and determine the causes of the data corruption.
Any .bmp-header has the following structure:
Offset |
Field length |
Field name |
Field value (in the given example) |
0x0000 |
Word |
file identifier |
must be 0x4D42 (BM in the text field) |
0x0002 |
DWord |
size of BMP file in bytes |
0x000E1036 (921654 bytes) |
0x0006 |
Word |
reserved, must be zero |
0x0000 |
0x0008 |
Word |
reserved, must be zero |
0x0000 |
0x000A |
DWord |
offset to start of image data in bytes |
0x00000036 (54 bytes) |
0x000E |
DWord |
size of BITMAPINFOHEADER structure, |
0x00000028 (40 bytes) |
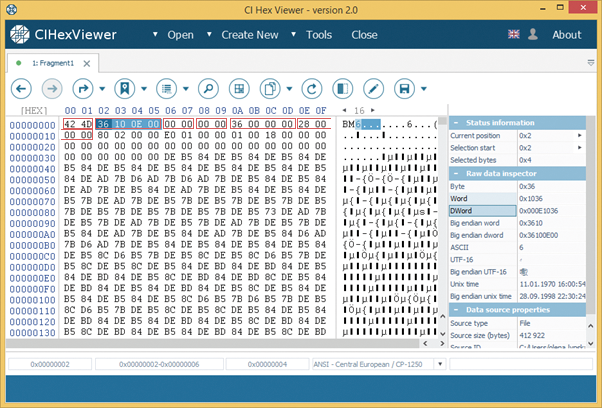
You can easily read the values of the hexadecimal data fields from the Data Inspector. To have the values displayed in the Inspector put the cursor at the field start and find the corresponding data type in the inspector table.
In our case, we find the value of the 4-byte field from offset 0x02 in little-endian direction in the DWord box.
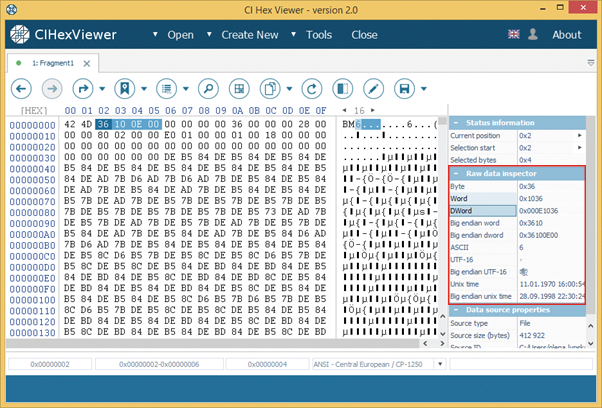
You can adjust the hexadecimal string length for a more convenient data viewing. To expand or to reduce the string length press the corresponding arrow in the top right corner or enter the necessary length in the drop-down box.
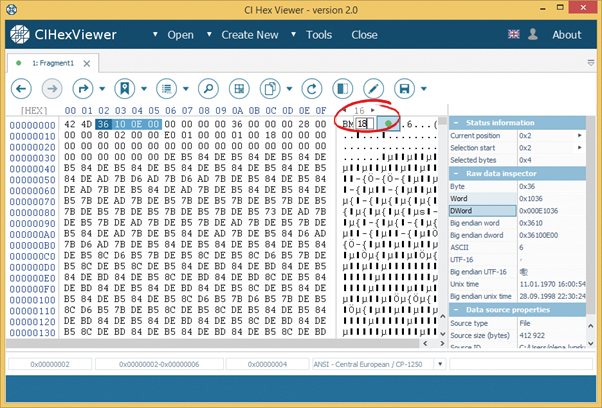
In our example, it was inconvenient to view the value of the 4-byte field from position 0x0E, because the first two bytes are in one line and the other two – in the following. We expand the row up to 18 bytes per hexadecimal string to make it hold the whole field length.

In the field from 0x0E to 0x11 stands the value 0x28 bytes what denotes the size of the .bmp info header. To check the value we go to the header end. To do this we mark 4 bytes from position 0x11 in the little-endian direction and select Follow link from the drop-down list for position change. The program reads the value of this hexadecimal field as a value to go to a new position. We select Bytes as the unit to calculate the new position and Forward, from current position as direction to jump to new position in the position change dialog.
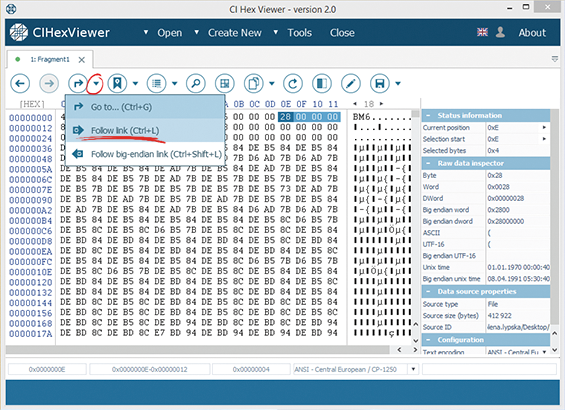
The file data begins with the position we have jumped to, meaning the end of the file header.
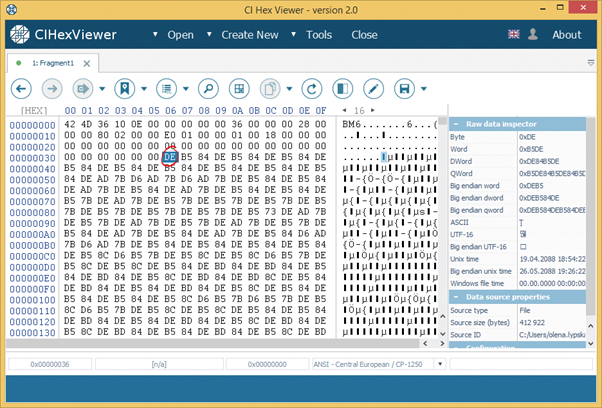
As a result of the data analysis we have established incompleteness of the file. The full file size is, judging from the header, 921 654 bytes, and in the raw data inspector as well as in the file properties we can see only 412 922 bytes. The second fragment is supposed to be a continuation of the first fragment.
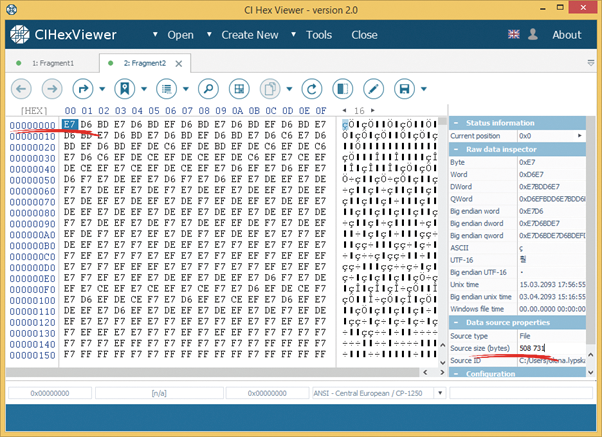
To prove this, we open the tab with the second fragment for viewing in the program and don’t find here any file header. At the same time, the file size is, judging on the source properties from the Inspector, 508 731 bytes, what makes, together with 412 922 bytes of the first fragment, the full size of the corrupted file.

With these results, we will try to repair the file manually. To start with, we switch the first fragment to the editing mode.
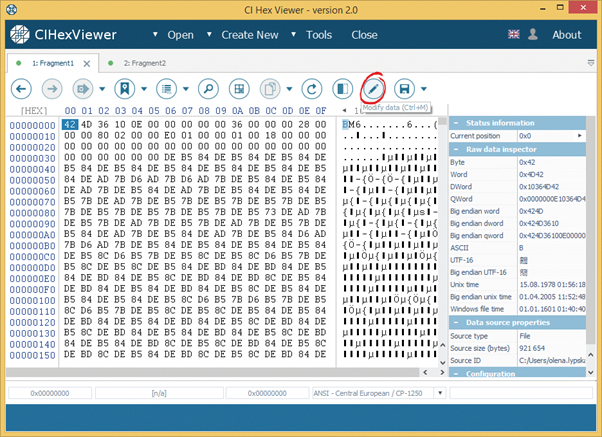
 The changes made to the file in the data-editing mode modify the data source. Any errors made during editing may lead to irreversible data loss.
The changes made to the file in the data-editing mode modify the data source. Any errors made during editing may lead to irreversible data loss.
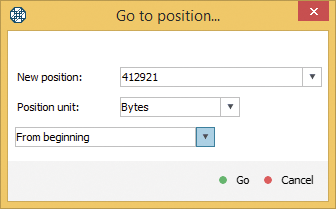
In the editing mode, we set the cursor position at the file end. To do this, we press Go to… and enter already known data size from the Inspector table as a number of bytes into the position change dialog.
With the cursor set at the file end, we append the second file fragment to the first one. To do this, we press Append a file from the tool bar for data editing.
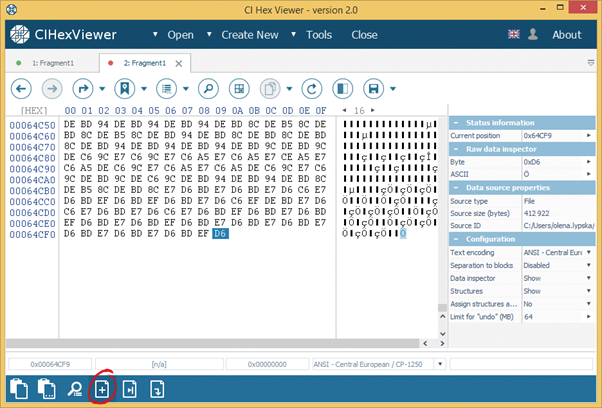
We choose the file of the second fragment from the dialog window. The data of this file will be added to the source file as it is.
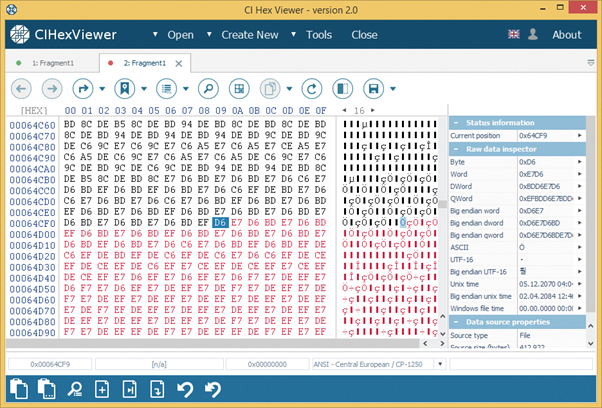
We save the changes pressing the button Save changes.
In addition, we renew the data in the source file pressing Refresh.
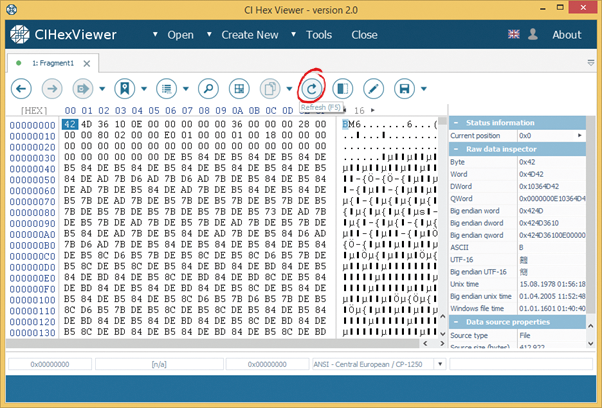
As a result, we get a complete file.
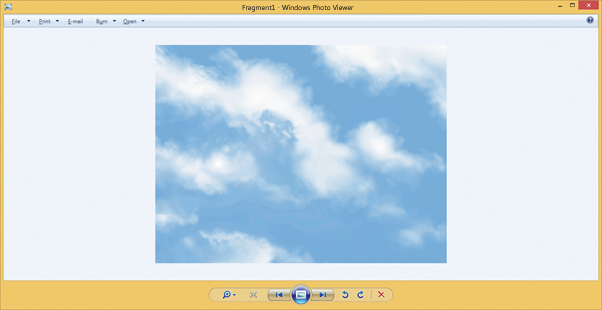
Summary:
Recovery of the corrupted file is carried out in two major stages. First, we have conducted raw data analysis and established that the corrupted file was incomplete. At the second stage, we have recovered the file in the editing mode by appending the missing fragment to the source file. In general, the above-described methods allow recovering files split into fragments.