RAID: the fundamentals
RAID (Redundant Array of Independent Disks) is a special technology for data storage organization where a number of separate disks is combined together to constitute one system. In such a system, as compared with traditional linear storages, the data is distributed across the drives in a way typical for certain RAID level. Each has its advantages and disadvantages, but the main idea of any RAID is a balance between maximum performance, increased reliability and full capacity of useful storage space. An operating system detects RAID as a single drive giving it its own mount point and treating all its disks as one and the same storage. All responsibility for correct system work is on RAID controller, which can be either hardware or software. Most commonly used RAID levels include: JBOD, which is not exactly RAID, as you trace no signs of redundancy or increased fault-tolerance here. Generally, this is Just a Bunch of Disks (not obligatory of the same size) combined together to consequently store data as the disks are filled one after another. This technique is also called disk spanning. Yet, the cost varies. 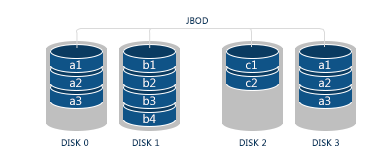 |
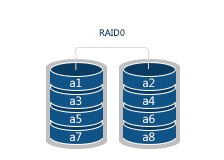
RAID 0 is based on data striping without redundancy. Each disk in the system is divided into separate segments – stripes. During writing, the data is cut into pieces equal to the stripe size and takes the disk stripes simultaneously: while one data part is still being written, the system starts input of the next one. In general, RAID 0 is the fastest in terms of input/output, but the least fault tolerant one. If any disk out of such a system happens to fail, all other data becomes unreadable. However, the speed is advantageous.
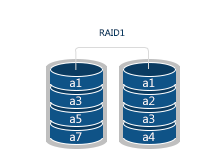
RAID 1 applies mirroring method. During write operation, the system creates an exact copy of the data on another drive. If one disk fails, the other one remains readable. This method has the highest level of reliability and the most expansive disk capacity, though. Disks work in pair only: the system stops working completely without all drives being in operation. RAID 1 is perfect where data backup is of vital importance.
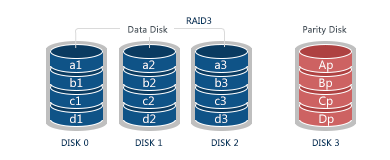
RAID 3 is the first to use parity. In combination with data striping similar to RAID 0, this system has a separate dedicated disk that stores parity for other disks. Due to its byte-level writing and separate disk to calculate and write the parity on, RAID 3 has not much to boast of in terms of speed. Such a scheme ensures system security, yet at expense of slow operation. For this reason, RAID 3 is not very popular. In case of failure, data is retrieved by intact disks and parity.
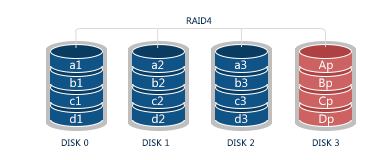
RAID 4 has the same scheme as RAID 3 (i.e. striping with dedicated parity) with one distinction: while RAID 3 operates at a byte level, this one handles data at a sector level. As a result, this resolves a write issue to some extent. Nevertheless, faster and more reliable RAID 5 has replaced RAID 4. As with RAID 3 this level is recovered by remaining disks plus parity disk.
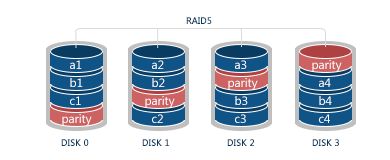
RAID 5 takes the principles of basic data striping similar to RAID 0 and redundancy of RAID 3, but is more progressive in its technology than its predecessors. Now no separate disk is dedicated to store parity information and it’s rather distributed among all data disks following special rotation schemes. This method speeded up writing, as the system doesn’t have to wait until the parity is calculated on a separate disk. If any of the drives fails, the data will be retrieved from the remaining drives and parity.
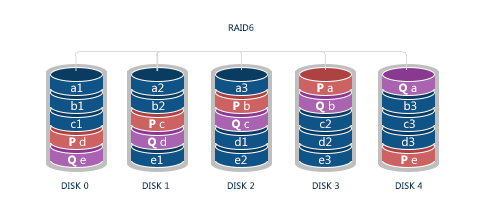
RAID 6 is a further step into higher reliability. This method implies two layers of parity distributed across all disks following special order and rotation schemes. Compared to other levels, RAID 6 allows for data recovery with two drives missing. This scheme is the most reliable one but the least cost-efficient, as plus one drive is used to store parity.
Note:
In case of failures you get a disassembled array with just a set of disks you need to have assembled before any further operations. CI Hex Viewer contains a special RAID-Builder Tool that allows assembling a variety of RAID levels providing possibility to analyze and edit storage data.